Consejos para empezar a resolver un bug
Aunque no se sepa el lenguaje de programación en el que este hecho un programa , se puede desarrollar o corregir las funciones donde se produce el error o simplemente para modificar por diversión .
Se tiene que tener en cuenta lo siguiente :
- Previo razonamiento lógico (al menos saber un lenguaje de programación) como recomendación aprender C y python , aprender a diferencias de hacer espaciados con space y con tab (usar ATom para codear seria mejor) , aprender a ser ordenado y a recibir recomendaciones lógicas para los loops.
- Aprender el uso de git
http://rogerdudler.github.io/git-guide/index.es.html
- Aprender el uso de jhbuild
http://akanooblinux.blogspot.pe/2016/11/ghost-line-bug-in-gedit-in.html
- Cuando se quiera buscar en donde ocurre el bug se debe recurrir a empezar a buscar dentro de todos los arhivos , probando palabras claves , para esto aprender comando linux y su uso como de grep
https://www.cyberciti.biz/faq/howto-use-grep-command-in-linux-unix/
-Consultar en foros y en los grupos del Irc de gnome publicando su codigo ya que siempre se puede mejorar el código.
- una parte importante de empezar a programar o corregir un pedazo de código a pesar que no sepas el lenguaje en el que esta programado es el sabe simplemente como funciona la función y para esto se puede buscar en las wikis de gnome o gtk donde explican al detalle los atributos y retornos de cada función .
https://developer.gnome.org/gtk3/stable/GtkTextView.html
sábado, 29 de abril de 2017
lunes, 20 de febrero de 2017
Explicacion del bug en el atajo Alt + Up/Down
Siguiendo con el bug en gedit encontrado , veremos la parte de código donde se produce este , estudiándolo para así llegar a la solución.
primeramente eh visto que el bug no es de gedit sino del widget GtksourceView que afecta no solo a gedit sino a toda aplicación (de gnome) que haga uso de esta .Entonces veamos el código donde se produce el bug :
*Segun lo visto este es el codigo donde se produce auqnue al modificarlo y compilarlo igual sigue apareciendo , lo que quiza no sea le codigo si alguien sabe si es el codigo del cambio d elinea al hacr atl+up porfavor confirmarmelo*
*Como recomendación , estudiar los archivos para saber que hace cada uno de ellos , usar búsqueda en los archivos (grep) para llegar mas rápido a la parte donde podríamos encontrar el bug*
Nos enfocaremos en el archivo gtksourceview.c , lo podemos ubicar en la carpeta fuente de GtksourceView (https://github.com/GNOME/gtksourceview).
Exactamente nos situaremos en la siguiente linea de codigo y estudiaremos su comportamiento para poner en evidencia el bug:


veamos solo algunas partes del código con un ejemplo :
*Se tendrán dos casos , cuando la linea se cambiara hacia arriba y cuando la linea se cambiara hacia abajo *
GtkTextBuffer *buf;
linea1\n
linea2\o
Tendremos un buffer que en un principio contendrá lo mostrado.
gtk_text_buffer_get_selection_bounds (buf, &s, &e): s y e serán los limites de acuerdo a donde este el cursor:
linea1\n (s)linea1\n(cursor)(e)
(s)linea2\o(cursor)(e) linea2\o
text = gtk_text_buffer_get_slice (buf, &s, &e, TRUE) : se cortara la lunea entre los limites (s,e) guardandolo en una variable text
Caso 1: Caso 2 :
text = linea2\o text = linea1\n
tk_text_iter_is_end (&e): veremos que si es un final de archivo es decir no presenta un retorno de carro\r o un salto de linea\n (Caso 1) se agregara a "text" el salto de linea teniendo :
tmp = g_strdup_printf ("%s\n", text); // se agrega el salto de linea
text = linea2\n
*Ojo en esta parte se nos asegura que sera la ultima linea del documento , justo el caso donde se produce el bug , mas adelante se vera que aqui viene la modificación para solucionar el bug solo viendo que en el buffer = linea1\n tendremos que borrar ese salto de linea*
gtk_text_buffer_delete (buf, &s, &e) : Se eliminara del buffer el text que este entre los limites(s,e) re localizando estos.
En el buffer se tendra ahora esto:
Caso 1: Caso 2 :
linea1\n(s,e) (s,e)linea2\n
f (down)
{
gtk_text_iter_forward_line (&e) : si es el segundo caso el iterador e se movera al final de la linea teniendo :
Caso 1: Caso 2 :
linea1\n(s,e) (s)linea2\o(e)
if (gtk_text_iter_is_end (&e)): si es final de archivo se agregara como en el caso 1 el salto de linea
gtk_text_buffer_insert (buf, &e, "\n", -1); //se inserta \n
En el buffer tendremos :
Caso 1: Caso 2 :
linea1\n(s,e) (s)linea2\n(e)
*Ojo aqui nos asegura que hay un \o es decir que es final del archivo por lo que esto nos indicara que estamos en el caso donde se produce el bug por lo que si se ve lo que hay en la variable text = linea1\n solo tendremos que borrar aqui ese salto de linea *
else { gtk_text_iter_backward_line (&e) : pasamos al caso 1 moviendo hacia al principio de linea el iterador e :
En el buffer tendremos :
Caso 1: Caso 2 :
(e)linea1\n(s) (s)linea2\n(e)
y en text tendremos
Caso 1: Caso 2 :
linea2\n linea1\n
gtk_text_buffer_insert (buf, &e, text, -1):juntaremos en el buffer lo que tenemos en text
Caso 1: Caso 2 :
(e)linea2\n (s)linea2\n
linea1\n(s) linea1\n(e)
Veamos aqui que se ve claramente el bug , al no borrar en los casos indicados el salto de linea "\n"
a la hora de la inserción este quedara aun en la linea , en las condicionales que nos indican que estamos al final del archivos tenemos que borrar ese \n.
----------
Al querer compilar GtksourceView en fedora25 hay algunos errores por lo que la solucione esta por probarse antes de publicarse.
primeramente eh visto que el bug no es de gedit sino del widget GtksourceView que afecta no solo a gedit sino a toda aplicación (de gnome) que haga uso de esta .Entonces veamos el código donde se produce el bug :
*Segun lo visto este es el codigo donde se produce auqnue al modificarlo y compilarlo igual sigue apareciendo , lo que quiza no sea le codigo si alguien sabe si es el codigo del cambio d elinea al hacr atl+up porfavor confirmarmelo*
*Como recomendación , estudiar los archivos para saber que hace cada uno de ellos , usar búsqueda en los archivos (grep) para llegar mas rápido a la parte donde podríamos encontrar el bug*
Nos enfocaremos en el archivo gtksourceview.c , lo podemos ubicar en la carpeta fuente de GtksourceView (https://github.com/GNOME/gtksourceview).
Exactamente nos situaremos en la siguiente linea de codigo y estudiaremos su comportamiento para poner en evidencia el bug:


veamos solo algunas partes del código con un ejemplo :
*Se tendrán dos casos , cuando la linea se cambiara hacia arriba y cuando la linea se cambiara hacia abajo *
GtkTextBuffer *buf;
linea1\n
linea2\o
Tendremos un buffer que en un principio contendrá lo mostrado.
gtk_text_buffer_get_selection_bounds (buf, &s, &e): s y e serán los limites de acuerdo a donde este el cursor:
linea1\n (s)linea1\n(cursor)(e)
(s)linea2\o(cursor)(e) linea2\o
text = gtk_text_buffer_get_slice (buf, &s, &e, TRUE) : se cortara la lunea entre los limites (s,e) guardandolo en una variable text
Caso 1: Caso 2 :
text = linea2\o text = linea1\n
tk_text_iter_is_end (&e): veremos que si es un final de archivo es decir no presenta un retorno de carro\r o un salto de linea\n (Caso 1) se agregara a "text" el salto de linea teniendo :
tmp = g_strdup_printf ("%s\n", text); // se agrega el salto de linea
text = linea2\n
*Ojo en esta parte se nos asegura que sera la ultima linea del documento , justo el caso donde se produce el bug , mas adelante se vera que aqui viene la modificación para solucionar el bug solo viendo que en el buffer = linea1\n tendremos que borrar ese salto de linea*
gtk_text_buffer_delete (buf, &s, &e) : Se eliminara del buffer el text que este entre los limites(s,e) re localizando estos.
En el buffer se tendra ahora esto:
Caso 1: Caso 2 :
linea1\n(s,e) (s,e)linea2\n
f (down)
{
gtk_text_iter_forward_line (&e) : si es el segundo caso el iterador e se movera al final de la linea teniendo :
Caso 1: Caso 2 :
linea1\n(s,e) (s)linea2\o(e)
if (gtk_text_iter_is_end (&e)): si es final de archivo se agregara como en el caso 1 el salto de linea
gtk_text_buffer_insert (buf, &e, "\n", -1); //se inserta \n
En el buffer tendremos :
Caso 1: Caso 2 :
linea1\n(s,e) (s)linea2\n(e)
*Ojo aqui nos asegura que hay un \o es decir que es final del archivo por lo que esto nos indicara que estamos en el caso donde se produce el bug por lo que si se ve lo que hay en la variable text = linea1\n solo tendremos que borrar aqui ese salto de linea *
else { gtk_text_iter_backward_line (&e) : pasamos al caso 1 moviendo hacia al principio de linea el iterador e :
En el buffer tendremos :
Caso 1: Caso 2 :
(e)linea1\n(s) (s)linea2\n(e)
y en text tendremos
Caso 1: Caso 2 :
linea2\n linea1\n
gtk_text_buffer_insert (buf, &e, text, -1):juntaremos en el buffer lo que tenemos en text
Caso 1: Caso 2 :
(e)linea2\n (s)linea2\n
linea1\n(s) linea1\n(e)
Veamos aqui que se ve claramente el bug , al no borrar en los casos indicados el salto de linea "\n"
a la hora de la inserción este quedara aun en la linea , en las condicionales que nos indican que estamos al final del archivos tenemos que borrar ese \n.
----------
Al querer compilar GtksourceView en fedora25 hay algunos errores por lo que la solucione esta por probarse antes de publicarse.
martes, 14 de febrero de 2017
Ghost Line Bug in gedit
In the documentation of gedit mentions many shortcuts, which only had to fulfill its function without adding something more. In the case of the shortcut ALT + Arrow_UP which should only interchange the line where the cursor is with the line above, this does not happen since it adds a line of more at the end of the text, for example if the original document had 3 lines ( As in the example of replica) when using the shortcut would end with 4 lines.
The shortcuts that gedit provides are following:
Problem
In many cases a plus line is not a major drawback, but if you were reading a set of data where the importance of the number of lines to count is important, as in files used to read a huge string of data for the Training of neurons, this generates an overflow problem.
Replica bug
The bug link found is as follows:
We will see that the following is validated:
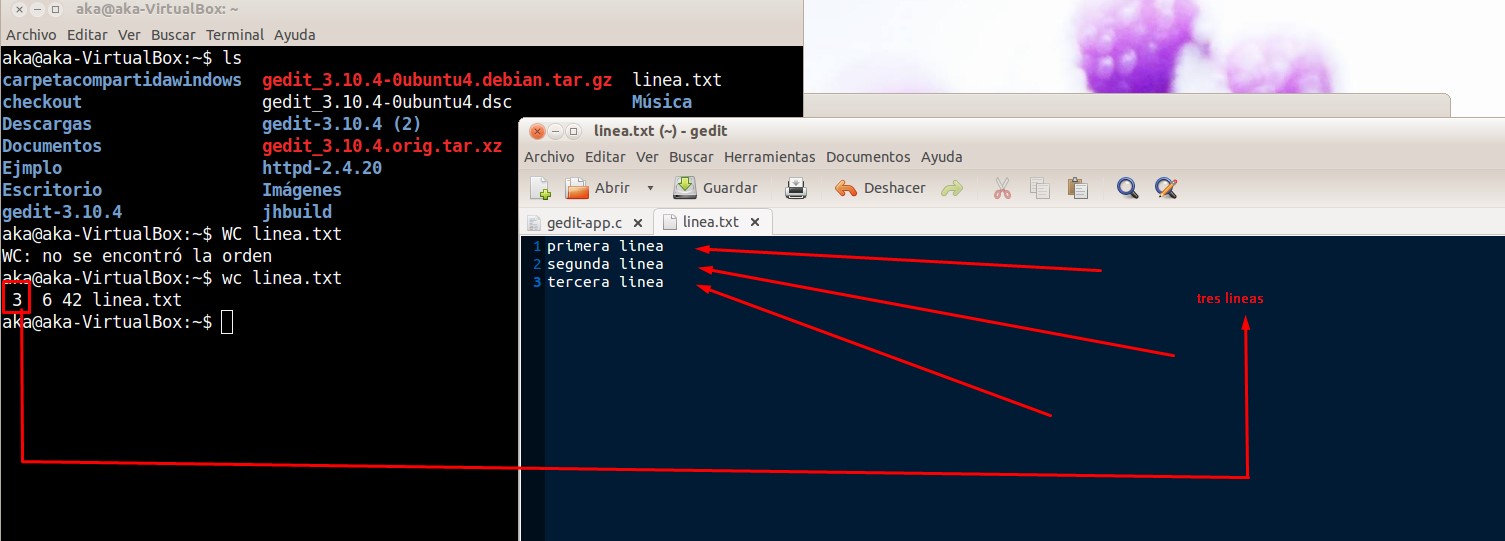
The original file has 3 lines as in the posed in the post
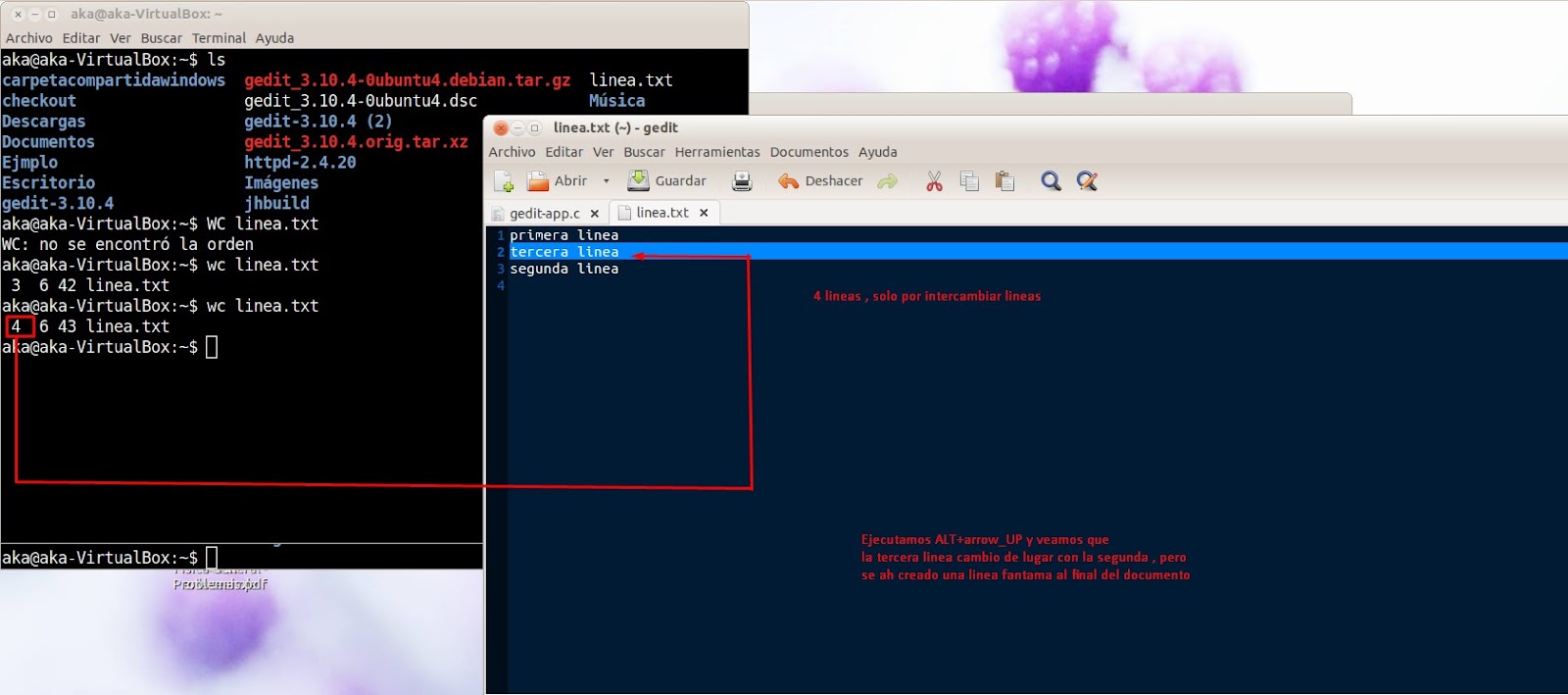
When running the shortcut ALT + arrow up let's see how a new phantom line is created when running wc in the test text, which verifies the mentioned bug.
Possible solution found
Hypothesis
The solution seems to be simple, despite not finding exactly the part of the code where it happens.
When you do a row exchange the following happens:
Line1 / o/n
Line2 / o/n
Line3 / o
Where "/ o" is the end of the line in the string and "/ n" is the line break , when the line change is done both a "delete" and "cut" line, storing the two strings to change in the following way:
Linea2 will be exchanged with Line3
Line3 is cut and buffered 1: Line3 / o
The cursor remains where I delete the line (here the error) being at the beginning thus:
Line1 / o/n
Line2 / o/n
|
From here you will copy from the cursor position all the previous string plus the space left at the time of cutting Line3, then:
Line2 + "Space left when cutting" to buffer 2: Line2 / o / n
Here it is appreciated that when "cut" ah is added a character more to the string. Then follows with:
Line1 / o
Paste buffer1 content: Line3 / o
Paste buffer2 content: Line2 / o / n
Appreciating more clearly the addiction of the line that causes the bug.
I do not know if it is part of the code of gedit or if it is already part of the use of gtk where is the code of change of lines.
The solution in this case would only be erased when doing the cut in additional line break.
Hypothesis
The solution seems to be simple, despite not finding exactly the part of the code where it happens.
When you do a row exchange the following happens:
Line1 / o/n
Line2 / o/n
Line3 / o
Where "/ o" is the end of the line in the string and "/ n" is the line break , when the line change is done both a "delete" and "cut" line, storing the two strings to change in the following way:
Linea2 will be exchanged with Line3
Line3 is cut and buffered 1: Line3 / o
The cursor remains where I delete the line (here the error) being at the beginning thus:
Line1 / o/n
Line2 / o/n
|
From here you will copy from the cursor position all the previous string plus the space left at the time of cutting Line3, then:
Line2 + "Space left when cutting" to buffer 2: Line2 / o / n
Here it is appreciated that when "cut" ah is added a character more to the string. Then follows with:
Line1 / o
Paste buffer1 content: Line3 / o
Paste buffer2 content: Line2 / o / n
Appreciating more clearly the addiction of the line that causes the bug.
I do not know if it is part of the code of gedit or if it is already part of the use of gtk where is the code of change of lines.
The solution in this case would only be erased when doing the cut in additional line break.
SO:Fedora25
miércoles, 30 de noviembre de 2016
Using jhbuild (compilar)
To test the source code of downloaded gedit has been made use of jhbuild in ubuntu, following the installation guide:

Obtaining the code in which i working:
Simple install procedure for gedit if you checked out the source code from git:
Download the most recent version of gedit
% git clone git://git.gnome.org/gedit
change to the toplevel directory
% cd gedit
generate the `configure' script
% ./autogen.sh
Modify code :D and
run the `configure' script
% ./configure
finaly
build gedit
% make
Modules, source code
References of similar cases:
Looking for possible solutions found the deactivation of the command Control + D
Where it shows that part of the code of use of this command

Edit:
The bug has not yet been fixed :(
martes, 27 de septiembre de 2016
Semáforos binario y multi variable
Vamos a intentar explicar un poco el uso de semáforos para ciertas acciones , lo mas simple posible , para esto tomaremos un caso de la vida diaria que es el esperar en una cola para entrar a un baño.
Primeramente el concepto de semáforo se puede apreciar como :
"Un semáforo es una variable entera que se incluye , para realizar con este un método de restringir o permitir el acceso a recursos compartidos ."
Con esto veamos el caso que se ah planteado , el de entrar a un baño.Imaginemos un baño con el numero de baños es variable , donde cada baño tiene una llave que se le da al usuario que lo vaya a usar .
En un primer caso podemos ver en el que solo existe un baño y su única llave para usarlo , en este caso todas las personas que lleguen van a tener que esperar al primer usuario que llego y que este termine su uso mientras los demás están en espera .Ya que el estado de este único baño puede ser en uso o no , se puede referir a un semáforo binario que tiene valores 0-1 comenzando su valor en 1 (como `primer uso en nuestro ejemplo) y tomando el valor 0 cuando el usuario sale .

Si en cambio nuestro baño tuviera un nuevo de baños con su respectivo nuevo de llaves , entonces el numero de llaves disponibles seria nuestro semáforo , distribuyendo así los usuarios en cada baño y generando así que cada uno se realice sin interrupción (ya que la llave es única en nuestro caso) , en este sentido el semáforo puede tomar varios valores dependiendo el caso.

Como algo adicional se puede decir de los mutexs que es una variable de exclusión mutua , que en nuestro caso se puede apreciar como la llave de cada baño , que sin ella no se puede acceder a este .
miércoles, 14 de septiembre de 2016
Algoritmos de planificación
Tomando en cuenta el problema de planificación de procesos planteado en el libro Sistemas Operativos de Tanenbaum , resolviendo este veremos como es el trabajo de 4 algoritmos de planificacion.
El problema es el siguiente :
a) Por turno circular.
b) Por prioridad.
c) Primero en entrar, primero en ser atendido (ejecutados en el orden 10, 6, 2, 4, 8).
d) El trabajo más corto primero.
Para (a), suponga que el sistema es multiprogramado y que cada trabajo recibe su parte equitativa de la CPU. Para los incisos del (b) al (d), suponga que sólo se ejecuta un trabajo a la vez hasta que termina. Todos los trabajos están completamente ligados a la CPU."
a)
Round Robin (Turno circular)
Uno de los algoritmos más antiguos, simples, equitativos y de mayor uso es el de turno circular (round-robin). A cada proceso se le asigna un intervalo de tiempo, conocido como quantum, durante el cual se le permite ejecutarse. Si el proceso se sigue ejecutando al final del cuanto, la CPU es apropiada para dársela a otro proceso. Si el proceso se bloquea o termina antes de que haya transcurrido el quantum la CPU pasa al siguiente proceso en la lista .
En el problema podemos elegir un quantum como el de 4min , es decir cada 4 min el CPU ira turnando los procesos hasta terminarlos.

Proceso A 20
Proceso B 18
Proceso C 4
Proceso D 10
Proceso E 20 Tiempo promedio : 14.4 min
b)
Por Prioridades
La idea básica es simple: a cada proceso se le asigna una prioridad y el proceso ejecutable con la prioridad más alta es el que se puede ejecutar.
Incluso hasta en una PC con un solo propietario puede haber varios procesos, algunos de ellos más importantes que los demás. Por ejemplo, un proceso demonio que envía correo electrónico en segundo plano debería recibir una menor prioridad que un proceso que muestra una película de video en la pantalla en tiempo real. Para evitar que los procesos con alta prioridad se ejecuten de manera indefinida, el planificador puede reducir la prioridad del proceso actual en ejecución en cada pulso del reloj (es decir, en cada interrupción del reloj). Si esta acción hace que su prioridad se reduzca a un valor menor que la del proceso con la siguiente prioridad más alta, ocurre una conmutación de procesos.
En el problema no se tomara en cuenta la interrupción del reloj.
Se puede apreciar que la ejecucion es muy diferente a la anterior , dadas las prioridades tomadas del problema.

Calculando el tiempo de espera promedio:
Proceso A 14
Proceso B 0
Proceso C 24
Proceso D 26
Proceso E 6 Tiempo promedio : 14 min
c)
Shortest Job First
Como dice su nombre el trabajo mas corto se realizara primero , es por lo general el que tiene tiempo de respuesta promedio mínimo para sistemas de procesamiento en lotes , pero no es muy aplicable en otros sistemas ya que no se sabe el tiempo del proceso mas corto , teniendo que hace un trabajo extra para saber esto.

Su tiempo de espera:
Proceso A 20
Proceso B 6
Proceso C 0
Proceso D 2
Proceso E 12 Tiempo promedio : 8 min
d)
Firts-Come, First-Served
No hay mucho que explicar , los procesos como van llegando se van a ir ejecutando mientras los que lleguen mientras alguno este ejecutándose van a una cola de espera .

Proceso A 0
Proceso B 10
Proceso C 16
Proceso D 18
Proceso E 22 Tiempo promedio : 13.2 minConclusión:
Teniendo en cuenta los tiempos promedios de respuesta 14.4 ,14, 8 ,13.2 min el como se esperaba mas corto fue el de primero en entrar primero en ser ejecutado , pero como ya se a dicho este no es tan eficiente en sistemas que no se sabe el costo de cada promedio . Los algoritmos que dan prioridades hacen un mejor uso de recursos y de procesamiento en segundo plano asi que para cada tipo de sistema podemos hacer uso de estos dependiendo con que recursos tenemos .
Suscribirse a:
Entradas (Atom)